
最近,Ollama正式发布了其最新版本——Ollama v0.8,为本地运行大型语言模型(LLM)带来了不少新功能和性能优化。作为一名科技博主,我必须说,这次更新真的让人眼前一亮!
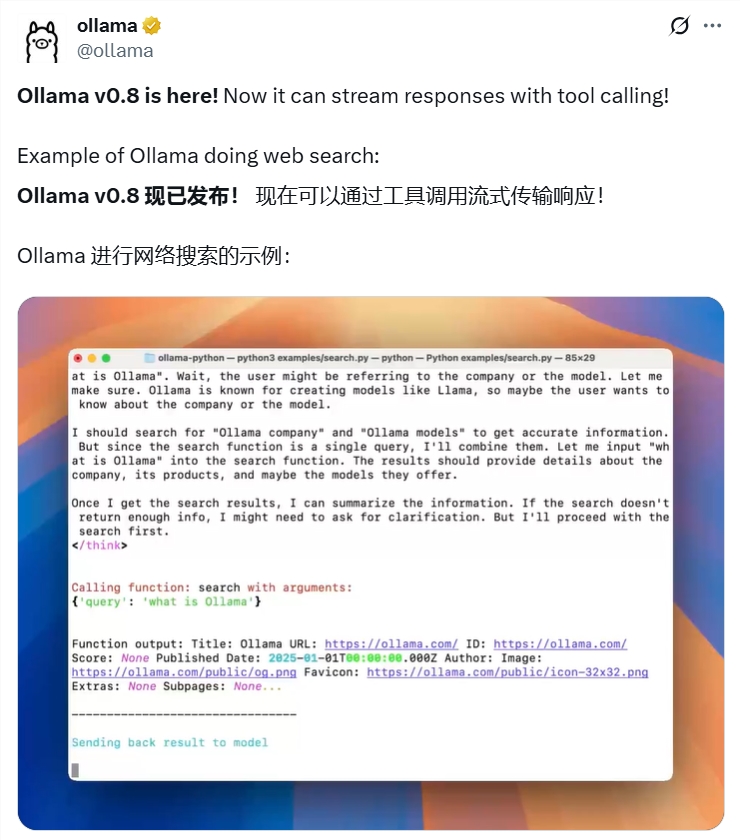
首先,流式传输响应绝对是这次升级的最大亮点之一。用户现在可以实时看到AI生成的内容,而不用再等待完整结果的输出。无论是复杂查询还是长文本生成,这种体验都显得更加流畅自然。
其次,Ollama v0.8新增了工具调用功能,让本地AI也能轻松连接外部世界。比如,通过调用网络搜索API,模型可以直接获取实时数据,甚至支持动态交互场景。虽然目前在高温度设置下可能会有些不稳定,但这一功能无疑为本地AI的应用场景打开了更多可能性。
性能方面,Ollama v0.8修复了一些模型运行中的内存泄漏问题,并优化了加载速度,特别是对Gemma3、Mistral Small3.1等模型的支持更为出色。同时,新增的滑动窗口注意力机制也让长上下文推理变得更加高效。
值得一提的是,Ollama依然保持开源传统,开发者可以通过简单的命令快速部署多种主流模型。此外,新增的AMD显卡支持以及与OpenAI Chat Completions API的部分兼容性,也让这款框架更具吸引力。
总的来说,Ollama v0.8不仅提升了本地AI的实用性,还进一步推动了其在教育、科研和企业级应用中的普及。如果你对本地运行LLM感兴趣,不妨试试这个版本吧!项目地址:GitHub
[hhw123pingdao]
温馨提示:
- 请注意,下载的资源可能包含广告宣传。本站不对此提供任何担保,请用户自行甄别。
- 任何资源严禁网盘中解压缩,一经发现删除会员资格封禁IP,感谢配合。
- 压缩格式:支持 Zip、7z、Rar 等常见格式。请注意,下载后部分资源可能需要更改扩展名才能成功解压。
- 本站用户禁止分享任何违反国家法律规定的相关影像资料。
- 内容来源于网络,如若本站内容侵犯了原著者的合法权益,可联系我们进行处理,联系微信:a-000000
📝留言定制 (0)